
İçindekiler
İnsan Genomu ve Veri Temsili Hakkında Arka Plan
İnsan genomu, haploid genom için yaklaşık 3,1 milyar baz çifti (bir kromozom seti) ve diploid genom için 6,2 milyar baz çifti (her iki set de, çünkü çoğu insan hücresi diploiddir) içeren, hemen hemen her hücrede bulunan DNA talimatlarının tam setidir. Bu baz çiftleri dört nükleotitten oluşur: Adenin (A), Timin (T), Sitozin (C) ve Guanin (G), genellikle dört harfli bir alfabeye benzetilir.
Bunu bilgisayar veri terimlerine çevirmek için, her baz çifti 2 bit kullanılarak kodlanabilir, çünkü dört olası kombinasyon vardır (örneğin, A=01, T=10, C=11, G=00). Bu, 4 baz çiftinin 1 baytta (8 bit) temsil edilebildiği verimli bir depolama sağlar. Bu yaklaşım, genom boyutunu bayt cinsinden tahmin etmek için biyoenformatikte standarttır.
Hücre Başına İnsan DNA’sındaki Toplam Veri
Sağlanan hesaplama, diploid insan genomunun 6 milyar baz çifti içerdiğini ve bunun şuna yol açtığını belirtir:
- ( 6 \times 10^9 ) baz çifti ( \times 2 ) bit/baz çifti ( = 12 \times 10^9 ) bit
- ( 12 \times 10^9 ) bit ( \div 8 ) bit/bayt ( = 1,5 \times 10^9 ) bayt
- Bu, hücre başına 1,5 GB’a eşittir.
Haploid genomun yaklaşık 3,1 milyar baz çifti olduğunu ve diploid genomun yaklaşık 6,2 milyar olduğunu doğrulamaktadır. Baz çifti başına 2 bit kullanarak:
- ( 6,2 \times 10^9 ) baz çifti ( \times 2 ) bit/baz çifti ( = 12,4 \times 10^9 ) bit
- ( 12,4 \times 10^9 ) bit ( \div 8 = 1,55 \times 10^9 ) bayt veya 1,55 GB.
Küçük tutarsızlık (1,5 GB – 1,55 GB) muhtemelen orijinal sorgudaki yuvarlamadan kaynaklanmaktadır, ancak her ikisi de beklenen aralıktadır. Bu nedenle, araştırmaların hücre başına toplam verinin küçük değişiklikleri kabul ederek yaklaşık 1,5 GB olduğunu öne sürmesi makuldür.
Tüm İnsan Vücudundaki Toplam Veri
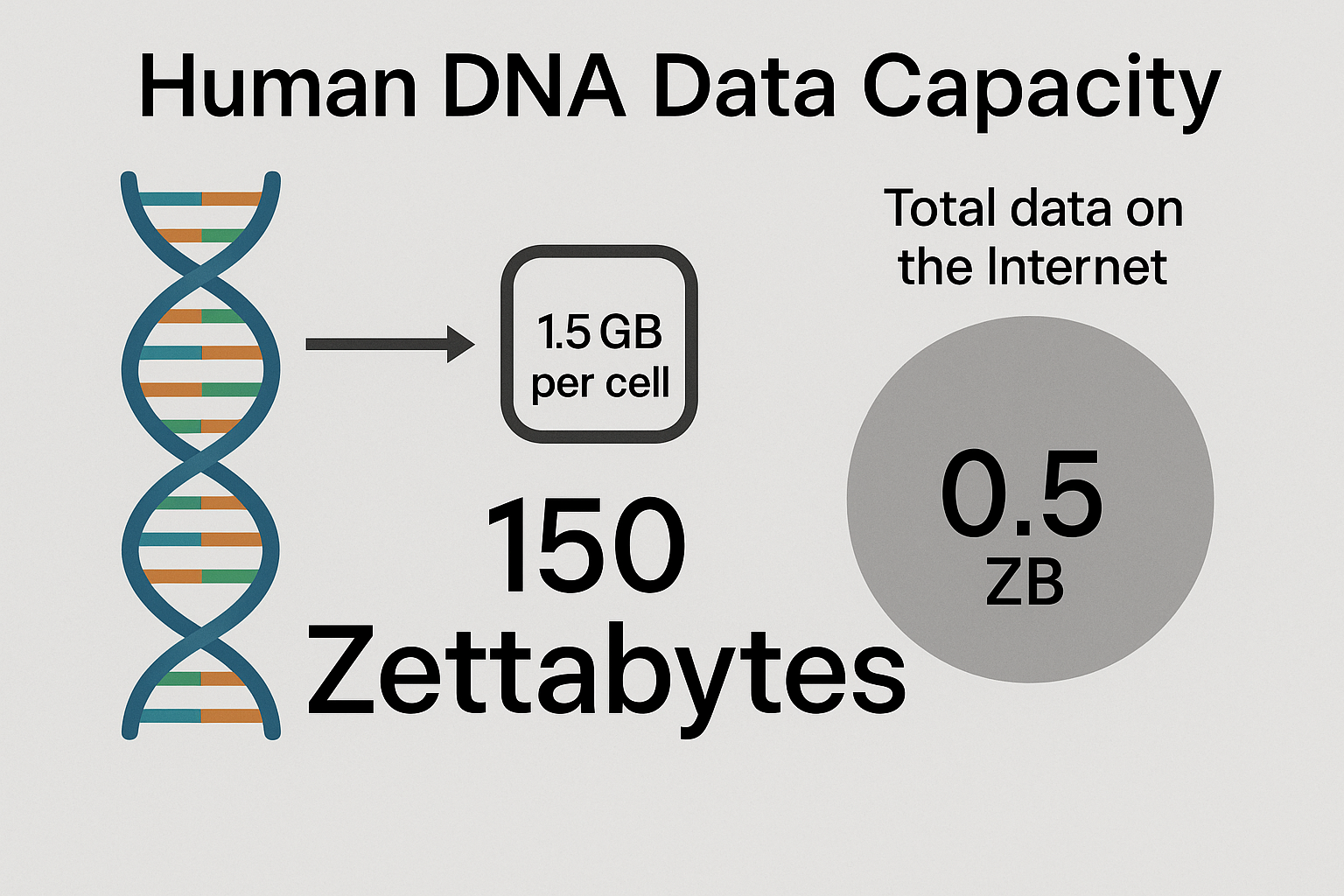
İnsan vücudundaki toplam genetik veriyi tahmin etmek için hücre sayısına ihtiyacımız var. Tahminler değişir, yaygın rakamlar 30 ila 40 trilyon arasındadır, ancak sorgu, çekirdeksiz kırmızı kan hücreleri de dahil olmak üzere tüm hücre tiplerini içermek için makul olan üst sınır olarak 100 trilyon kullanır. 100 trilyon hücre kullanılarak:
- ( 100 \times 10^{12} ) hücre ( \times 1.5 \times 10^9 ) bayt/hücre ( = 150 \times 10^{21} ) bayt
- Bu 150 Zettabayttır (ZB), çünkü 1 ZB = ( 10^{21} ) bayttır.
Bağlam için, son tahminler tüm internet verilerinin yaklaşık 0,5 ZB olduğunu öne sürüyor Medium: İnsan Genomu Ne Kadar Büyük?, bu da vücudun genetik verilerini 300 kat daha büyük hale getiriyor. Ancak, bu hesaplama her hücrenin DNA’sının benzersiz olduğunu varsayıyor, bu da tamamen doğru değil, çünkü çoğu hücre mutasyonlar dışında aynı DNA’yı paylaşıyor. Yine de, ham veri kapasitesi için 150 ZB geçerli bir üst tahmindir.
Cinsel İlişki Sırasında Veri Akışı
Cinsel ilişki sırasında, genetik veriler haploid olan ve bir kromozom seti (yaklaşık 3 milyar baz çifti) taşıyan sperm hücreleri aracılığıyla aktarılır. Sorgu şunları hesaplar:
- Her sperm: ( 3 \times 10^9 ) baz çifti ( \times 2 ) bit/baz çifti ( = 6 \times 10^9 ) bit ( = 750 \times 10^6 ) bayt = 750 MB.
- Boşalma başına 180 milyon spermle:
- ( 180 \times 10^6 ) sperm ( \times 750 \times 10^6 ) bayt/sperm ( = 135 \times 10^{12} ) bayt.
Terabaytlara Dönüştürme (1 TB = ( 10^{12} ) bayt):
- ( 135 \times 10^{12} ) bayt ( \div 10^{12} ) bayt/TB = 135.000 TB.
Doğrulama, haploid genomun biraz daha fazla olduğunu, yaklaşık 3,1 milyar baz çifti olduğunu ve sperm başına 775 MB’a yol açtığını gösteriyor, ancak sorgu ile tutarlılık için 750 MB kullanılıyor. 180 milyonluk sperm sayısı tipiktir, bu nedenle toplam 135.000 TB olası görünüyor, ancak yalnızca bir sperm yumurtayı 750 MB kullanarak döllemekte ve geri kalanı “kaybolmaktadır.”
Bilgisayar Sistemleriyle Karşılaştırma
Sorgu, DNA ile bilgisayar verileri arasında bir benzetme yapıyor ve bilgisayarların ikili kod (0’lar ve 1’ler) kullandığını, DNA’nın ise dört baz kullandığını belirtiyor. Bu karşılaştırma yerindedir, çünkü her iki sistem de bilgi depolar, ancak DNA’nın depolanması biyokimyasaldır ve proteinler ve RNA’lar gibi dizinin ötesinde karmaşık etkileşimleri içerir. Sorgunun 4 baz çifti başına 1 bayt (her biri 2 bit olan 4 baz için 8 bit) hesaplaması verimlidir ve biyoenformatik uygulamalarıyla uyumludur.
Hücre Bölünmesi ve Veri Kopyalama
İlginç bir ayrıntı, hücre bölünmesi sırasında kopyalanan verilerdir, örneğin kan hücresi üretimi. Sorgu, saniyede 2,6 milyon yeni kan hücresi olduğunu ve her birinin kopyalanması için 1,5 GB DNA gerektiğini belirtir:
- ( 2,6 \times 10^6 ) hücre/saniye ( \times 1,5 \times 10^9 ) bayt/hücre ( = 3,9 \times 10^{15} ) bayt/saniye
- Bu, 3.900 TB/saniyedir ve biyolojik sistemlerdeki muazzam veri işlemeyi, mevcut bilgisayar kapasitelerinin çok ötesinde vurgular.
Sınırlamalar ve Karmaşıklıklar
Sorgu, genomik verilerin yalnızca diziyi değil, bu hesaplamalarda yakalanmayan epigenetik modifikasyonlar ve düzenleyici mekanizmalar da dahil olmak üzere daha fazlasını içerdiğini kabul eder. Ek olarak, genomun büyük bir kısmı kodlamayan (“çöp DNA”) olduğundan gerçek “işlevsel” veriler daha küçük olabilir. Ancak, ham veri kapasitesi için hesaplamalar geçerlidir.
Tablo: Hesaplamaların Özeti
Aşağıda netlik sağlamak için temel hesaplamaları özetleyen bir tablo bulunmaktadır:
| Yön | Değer | Notlar |
|---|---|---|
| Hücre başına diploid genom boyutu | ~1,5 GB | 6 milyar baz çiftine dayalı, her biri 2 bit |
| Vücuttaki toplam hücre | 100 trilyon | Üst tahmin, tüm hücre tiplerini içerir |
| Toplam vücut genetik verileri | 150 ZB | 100 trilyon hücre × 1,5 GB |
| Sperm genom boyutu | ~750 MB | Haploid, diploidin yarısı, 3 milyar baz çifti |
| Boşalma başına sperm sayısı | 180 milyon | Tipik ortalama |
| Toplam veri aktarımı | 135.000 TB | 180 milyon × 750 MB, yalnızca 750 MB kullanıldı |
Keşif
İnsan Genomu Boyutu Hakkında Arka Plan
İnsan genomu, yakın zamanda yapılan dizileme çalışmalarıyla belirlenen haploid genom için yaklaşık 3,055 milyar baz çiftinden (bp) oluşan, hemen hemen her hücrede bulunan DNA talimatlarının tam kümesidir. Bu boyut, önemli kısımları tekrarlayan diziler olmak üzere hem protein kodlayan hem de kodlamayan DNA’yı içerir. Bu kapasitenin keşfi, erken biyokimyasal teknikleri, büyük ölçekli dizileme projelerini ve modern teknolojik gelişmeleri içeriyordu.
DNA Yeniden İlişkilendirme Kinetiğini Kullanan İlk Tahminler (1970’ler-1980’ler)
Büyük ölçekli genom dizilemesinin ortaya çıkmasından önce, 1970’lerde ve 1980’lerin başında, bilim insanları genom boyutunu tahmin etmek için DNA yeniden ilişkilendirme kinetiğine güveniyorlardı. Bu yöntem, DNA’nın denatüre edilmesini (çift zincirlerin ayrılmasını) ve sıcaklık düşürüldüğünde ne kadar çabuk yeniden birleştiğini (çift zincirleri yeniden şekillendirdiğini) ölçmeyi içerir; bu, DNA dizilerinin karmaşıklığına ve tekrarına bağlıdır.
- 1978 tarihli bir çalışma, “İnsan spermatozoa genomu. DNA yeniden birleşme kinetiği ile analiz” PubMed: 737181, tekrarlanan (sperm için %12,1, lökositler için %9,2) ve tek kopyalı dizilerin (sperm için %59, lökositler için %64) oranlarına odaklanarak insan spermatozoa DNA’sını lökosit DNA’sıyla karşılaştırarak analiz etti. Toplam genom boyutunu doğrudan belirtmese de, daha geniş tahminlerde kullanılan bileşimin anlaşılmasına katkıda bulundu. – 1981 tarihli bir çalışma, “İnsan DNA’sının yeniden birleşme eğrisi değiştirildi” PubMed: 6261822, S1 nükleaz-dioksan prosedürünü kullanarak insan genom boyutunu özellikle 2,5 × 10^9 nükleotid çifti (2,5 milyar bp) olarak tahmin etti. Bu yöntem yüksek moleküler ağırlıklı DNA’yı analiz etti ve toplam DNA’nın %85-90’ının benzersiz dizilerden oluştuğunu, daha önce bildirilenden daha yüksek bir tahmin olduğunu öne sürdü.
Bu erken tahminler çok önemliydi ve daha sonra doğrulanan boyutlara yakın olan yaklaşık 2,5 ila 3 milyar bp’lik bir temel değer sağladı. Teknik, “Dört amfibi türünde genom büyüklüğüne göre DNA yeniden birleşme kinetiği” PubMed: 826380 gibi çalışmalarda görüldüğü gibi çeşitli türler için yaygın olarak kullanıldı; bu çalışmalarda benzer yöntemler amfibilere uygulandı ve insan genom büyüklüğü tahminine uygulanabilirliği vurgulandı.
İnsan Genomu Projesinin Kavramsallaştırılması (1980’lerin Ortası)
1980’lerin ortalarına gelindiğinde, bilim camiası genomun büyüklüğü hakkında kabaca bir anlayışa sahipti ve bu, İnsan Genomu Projesi’nin (HGP) önerilmesinde önemli bir faktördü. HGP, 1984’te ABD Enerji Bakanlığı tarafından 1984’ten 1986’ya kadar düzenlenen bilimsel toplantılarda tartışmalarla tasarlandı ve ABD Ulusal Araştırma Konseyi tarafından 1988 tarihli raporunda Nature: İnsan genomunun ilk dizilenmesi ve analizi onaylandı.
- 1988’de özetlenen projenin hedefleri arasında, daha önceki biyokimyasal tahminlere ve kapsamlı bir haritaya ihtiyaç duyulmasına dayanarak yaklaşık 3 milyar bp olduğu tahmin edilen tüm insan genomunun dizilenmesi yer alıyordu. Bu, projenin kökenlerini ayrıntılı olarak açıklayan İnsan Genomu Projesi Bilgi Formu İnsan Genomu Projesi Bilgi Formu gibi kaynaklarda yansıtıldı.
İnsan Genomu Projesi ve Taslak Diziler (1990–2003)
Ekim 1990’da başlatılan ve Nisan 2003’te tamamlanan HGP, insan genomunu dizilemek için çığır açıcı bir çabaydı ve daha önceki tahminleri doğruladı ve geliştirdi. Önemli kilometre taşları şunlardır:
- 1990–2000: İlk çabalar, genom boyutunun yaklaşık 3 milyar bp olduğu tahminleriyle dizileme teknolojilerinin geliştirilmesine odaklandı. 7 Ekim 2000’de, bir taslak dizi, “İnsan genomunun ilk dizilenmesi ve analizi”nde Doğa: İnsan genomunun ilk dizilenmesi ve analizi belirtildiği gibi, toplamın 3.200 Mb (3,2 milyar bp) olduğunu ve ökromatik kısmın 2,9 Gb olduğunu tahmin etti. – 2001: İlk taslak yayınlandı ve genomun yaklaşık %83’ünü kapsıyordu (yaklaşık 2,9 milyar bp), geri kalanı ise telomer ve sentromerlerdeki tekrarlayan bölgelerdi, “İnsan Genomu – Genomlar – NCBI Kitaplığı”nda İnsan Genomu – Genomlar – NCBI Kitaplığı ayrıntılı olarak açıklandığı gibi.
- 2003: Proje tamamlandı ve dizi genomun %92’sini kapsıyordu, haploid genom için boyutun İnsan Genomu Projesi Zaman Çizelgesi’nde İnsan Genomu Projesi Zaman Çizelgesi görüldüğü gibi yaklaşık 3,2 milyar bp olduğu doğrulandı.
Bu dönem, HGP’nin doğrudan dizileme yoluyla daha doğru bir ölçüm sağlaması, daha önceki tahminlerle uyumlu olması ancak boşlukları doldurması ve hassasiyeti artırmasıyla anlayışı geliştirdi.
Modern Gelişmeler ve Tam Dizileme (2000’ler-2020’ler)
Son çabalar, özellikle dizileme teknolojisindeki gelişmelerle insan genom boyutunu daha da geliştirdi:
- 2000-2021: “İnsan Genomu Projesi – Wikipedia”da İnsan Genomu Projesi – Wikipedia belirtildiği gibi, 2005 yılına kadar yaklaşık %92’si doldurulan iyileştirilmiş taslaklar duyuruldu. Odak noktası ökromatik bölgelerdi ve heterokromatik bölgeler tamamlanmamıştı.
- 2022: Telomer-Telomere (T2T) Konsorsiyumu, 31 Mart 2022’de sentromerik uydu dizileri ve akrosentrik kromozomların kısa kolları dahil olmak üzere tüm boşlukları dolduran ilk gerçekten tamamlanmış diziyi duyurdu. “İnsan genomunun tam dizisi” Science: İnsan genomunun tam dizisi‘nde ayrıntılı olarak açıklanan bu dizi, nükleer DNA için toplam boyutu 3.054.815.472 bp ve 16.569 bp mitokondriyal genom olarak doğruladı ve haploid genom boyutunu 3,055 milyar bp’ye çıkardı.
Zaman İçinde Tahminlerin Karşılaştırılması
Aşağıda, insan genomu boyutu keşfinin tarihindeki temel tahminleri ve kilometre taşlarını özetleyen bir tablo bulunmaktadır:
| Yıl | Tahmin (Milyar Baz Çifti) | Yöntem | Ayrıntılar |
|---|---|---|---|
| 1978 | ~2,5 | DNA yeniden birleşme kinetiği | Spermatozoa DNA’sının lökositlerle karşılaştırılması PubMed: 737181 |
| 1981 | 2,5 | DNA yeniden birleşme kinetiği | Yüksek moleküler ağırlıklı DNA, %85–90 benzersiz diziler PubMed: 6261822 |
| 1988 | ~3 | HGP planlaması için kavramsal | Daha önceki tahminlere dayalı olarak Ulusal Bilimler Akademisi raporunda özetlenmiştir |
| 2000 | 3,2 | Taslak dizi (%25 tamamlandı) | Ökromatik kısım 2,9 Gb Nature: İlk dizileme |
| 2003 | 3.2 | HGP tamamlanması, %92 kapsama | Doğrulanmış haploid genom boyutu İnsan Genomu Projesi Bilgi Formu |
| 2022 | 3.055 | T2T Konsorsiyumu, tam dizi | Tüm kromozomlar dahil boşluksuz Bilim: Tam dizi |
Sınırlamalar ve Karmaşıklıklar
DNA yeniden birleşme kinetiği kullanılarak yapılan erken tahminler dolaylıydı ve dizi karmaşıklığı ve tekrarı hakkındaki varsayımlara dayanıyordu; bu da eksik veya fazla tahminlere yol açabilirdi. HGP ve sonraki çabalar bunları açıklığa kavuşturdu, ancak kodlamayan DNA’nın (başlangıçta “çöp” olarak kabul edildi) işlevsel önemi, genom boyutunu veri kapasitesi açısından nasıl yorumladığımızı etkileyen devam eden bir araştırma konusu olmuştur.
İleri Okuma
- Avery, O. T., MacLeod, C. M., & McCarty, M. (1944). Studies on the chemical nature of the substance inducing transformation of pneumococcal types: Induction of transformation by a desoxyribonucleic acid fraction isolated from pneumococcus type III. Journal of Experimental Medicine, 79(2), 137–158.
- Watson, J. D., & Crick, F. H. C. (1953). Molecular structure of nucleic acids: A structure for deoxyribose nucleic acid. Nature, 171(4356), 737–738.
- Sinsheimer, R. L. (1959). The biological significance of the structure of DNA. American Scientist, 47(2), 241–263.
- Church, G. M., Gao, Y., & Kosuri, S. (2012). Next-generation digital information storage in DNA. Science, 337(6102), 1628.
- Goldman, N., Bertone, P., Chen, S., Dessimoz, C., LeProust, E. M., Sipos, B., & Birney, E. (2013). Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature, 494(7435), 77–80.
- Grass, R. N., Heckel, R., Puddu, M., Paunescu, D., & Stark, W. J. (2015). Robust chemical preservation of digital information on DNA in silica with error-correcting codes. Angewandte Chemie International Edition, 54(8), 2552–2555.
- Erlich, Y., & Zielinski, D. (2017). DNA Fountain enables a robust and efficient storage architecture. Science, 355(6328), 950–954.
- Organick, L., Ang, S. D., Chen, Y. J., Lopez, R., Yekhanin, S., Makarychev, K., … & Ceze, L. (2018). Random access in large-scale DNA data storage. Nature Biotechnology, 36(3), 242–248.
- Blawat, M., Gaedke, K., Huetter, I., Chen, X. M., Turczyk, B., Inverso, S., … & Church, G. M. (2016). Forward error correction for DNA data storage. Procedia Computer Science, 80, 1011–1022.
- Chandak, S., Tatwawadi, K., Wong, K., Wakayama, Y., Tabatabaei Yazdi, S. M. H., & Milenkovic, O. (2020). Improved read/write cost tradeoff in DNA-based data storage using LDPC codes. Nature Communications, 11, 6165.
- BiteSize Bio: How Much Information is Stored in the Human Genome
- Wikipedia: Human Genome
- Human Genome Project: Information